
 Kotlin Android, Entendendo e Primeiro ProjetoAndroid
Kotlin Android, Entendendo e Primeiro ProjetoAndroidNoSQL Essencial - Um Guia Conciso para o Mundo Emergente da Persistência Poliglota
(6248)
Go-ahead
Prototipagem Android

TítuloAndroid: Prototipagem Profissional de Aplicativos
CategoriasAndroid, Design, Protótipo
AutorVinícius Thiengo
Vídeo aulas186
Tempo15 horas
ExercíciosSim
CertificadoSim
Acessar CursoCategoriasAndroid, Design, Protótipo
AutorVinícius Thiengo
Vídeo aulas186
Tempo15 horas
ExercíciosSim
CertificadoSim
Quer aprender a programar para Android? Acesse abaixo o curso gratuito no Blog.
Lendo

TítuloCraftsmanship Limpo: Disciplinas, Padrões e ética
CategoriaDesenvolvimento Web
Autor(es)Robert C. Martin
EditoraAlta Books
Edição1ª
Ano2023
Páginas416
CategoriaDesenvolvimento Web
Autor(es)Robert C. Martin
EditoraAlta Books
Edição1ª
Ano2023
Páginas416

Capa do livro "NoSQL Essencial"
Título
NoSQL Essencial - Um Guia Conciso para o Mundo Emergente da Persistência Poliglota
Categoria
Banco de Dados
Autor(es)
Martin Fowler, Pramod Sadalage
Editora
Novatec
Ano
2013
Edição
1ª
Páginas
220
Tudo bem?
Terminada a leitura do livro "NoSQL Essencial - Um Guia Conciso para o Mundo Emergente da Persistência Poliglota" de Martin Fowler e Pramod Sadalage, respectivamente cientista e consultor na ThoughtWorks.
Se você é ávido seguidor de conteúdos de engenharia e arquitetura de software deve conhecer Martin Fowler, ele é autor de títulos como: Refatoração - Aperfeiçoando o Projeto de Código Existente [1999]; e UML Essencial - Um Breve Guia para Linguagem Padrão [2000].
Antes de iniciar os comentários sobre o livro, em minha opinião ao menos conhecer a teoria de bases de dados NoSQL é algo importante a qualquer desenvolvedor ou analista de software, principalmente no contexto mobile, onde um aplicativo pode ficar popular tão rapidamente como um vídeo de YouTube.
Certo, mas se o app ficar popular a ponto de ter milhões de acesso em poucos dias, qual a necessidade de conhecer também as bases NoSQL?
Continue lendo, no decorrer do artigo sobre o livro você entenderá a relação entre: milhares de acesso ➙ dados massivos ➙ NoSQL.
NoSQL Essencial é sem sombra de dúvidas um dos melhores títulos sobre bancos de dados criados para lidar com dados em grande escala sem utilizar a conhecida linguagem SQL e também sendo executado, quase sempre, em clusters, permitindo a barata (R$) expansão horizontal.
Ok Thiengo, mas eu ainda não trabalho com o Firebase Database, a popular base NoSQL presente também para aplicativos o Android. Você mesmo assim me recomendaria tomar conhecimento sobre bases NoSQL?
Sim. Pois ter conhecimento somente de bases relacionais SQL te limitará em muito, principalmente se você já enfrentou problemas de velocidade, isso pode acabar te levando a desistir de projetos que com uma base NoSQL ele seria desenvolvido sem problemas na camada de dados.
A partir daqui colocarei meus comentários sobre o livro NoSQL Essencial, comentários detalhados que lhe ajudarão na escolha de investir ou não no estudo de tecnologias NoSQL.
O livro está dividido em duas partes: Compreender e Implementar. Ao todo somando 15 capítulos.
Antes de prosseguir, não esqueça de se inscrever na 📩 lista de e-mails para receber os conteúdos exclusivos e em primeira mão.
Parte I - Compreender
Os capítulos desta parte vão de: um ao sete, incluindo o prefácio. Esses têm muito mais teorias gerais sobre bancos de dados NoSQL, e um pouco de SQL, e poucas menções a tecnologias e marcas em específico.
Se você já está em trabalho com alguma base NoSQL e falta tempo para ler um livro por completo, você pode seguramente ler do prefácio ao capítulo sete para já ter um impacto no uso do banco de dados de sua escolha. O restante você vai lendo aos poucos.
Prefácio
Primeiro, se está esperando um livro recheado de algoritmos e tutoriais de testes com bases NoSQL: este não é esse tipo de livro.
Logo no prefácio os autores alertam que NoSQL Essencial é uma excelente leitura para aquela viagem longa.
O objetivo aqui é dar ao leitor portfólio teórico para saber ao menos conduzir uma discussão sobre quais tipos de bancos de dados utilizar em projeto.
Um ponto curioso do prefácio é que os autores informam o público alvo sendo de gestores e analistas de sistemas, quando na verdade qualquer profissional programador ou analista seguramente irá ter ganhos consideráveis em conhecimento quando terminada a leitura do livro.
Um ponto importante ainda nesta parte do livro é quando os autores mostram que o livro não tem como parte do objetivo informar que as bases relacionais SQL estão obsoletas e que as bases NoSQL vieram para substituía-las, até porque isso não é verdade.
As bases NoSQL existem principalmente para atender a domínios de problemas de dados massivos, domínios não muito eficientes com as bases relacionais SQL e o conhecido modelo transacional ACID presente nelas.
Por que o termo "relacional SQL" e não somente "relacional"?
Você entenderá no decorrer do conteúdo, mas adiantando: existem bases relacionais NoSQL.
Capítulo 1 - Por que NoSQL?
Começando com o pé direito o conteúdo principal do livro, este capítulo contém algo que dou muito valor em qualquer livro de tecnologia: contexto histórico. O que veio antes? Por que veio antes? Por que agora essa nova tecnologia? ...
Os autores falam o porquê de as bases relacionais SQL terem vencido, mercadologicamente falando, até mesmo os bancos de dados de objetos, bancos estes que chegaram a ser a grande aposta da comunidade de desenvolvedores na década de 90.
E em resumo, acredite, as bases relacionais SQL também perduraram, venceram, por serem já padronizadas e amplamente utilizadas em mercado. Junte a isso o velho problema do ser humano de "resistir a mudança".
Os desenvolvedores e administradores de bancos de dados viram uma cobrança de mudança chegar quando na verdade não havia tanta necessidade assim, tendo em mente que o principal problema até então era a incompatibilidade de impedância das bases relacionais SQL que exigia o processo de mapeamento objeto-relacional, nada que justifica-se a mudança para bases de dados de objetos, por exemplo, que acarretaria em curva de aprendizagem e outros.
Quando os autores iniciam a abordagem as bases NoSQL, algo curioso é informado: que o nome NoSQL na verdade surgiu como sendo o melhor termo para ser utilizado como hashtag do Twitter referente a uma reunião que ocorreria em 2009 somente para envolvidos em desenvolvimentos de bases de dados open source e que tivessem como foco clusters ou massas de dados.
Antes que eu esqueça, o principal motivo do surgimento das bases NoSQL foi o problema de massas de dados, algo que primeiro foi enfrentado pelas empresas Google e Amazon, que logo depois da liberação dos artigos sobre o BigTable (Google) e o DynamoDB (Amazon) despertou a criação de várias outras bases NoSQL, muitas open source.
Voltando a definição do nome... sim, NoSQL é o termo utilizado até hoje, pois a principal características compartilhada por todas essas bases que trabalham com massas de dados é a não utilização da linguagem SQL.
O capítulo, como alguns outros, termina com os pontos-chave. Essa parte é muito útil para relembrar os conteúdos abordados, útil a nível de ser similar aos benefícios do uso de mapas mentais.
Importante: muita atenção na leitura do tópico sobre "bancos de dados de integração" e "bancos de dados de aplicativos", conteúdo útil principalmente por ser relacionado ao que utilizamos hoje em dia, desenvolvimento Web e mobile.
Uma nota de leitor: o último parágrafo do tópico de "bancos de dados de integração e de aplicativos" utiliza o termo "banco de dados relacional" como sinônimo de "banco de dados de integração", quando isso não é verdade. Nesse trecho final, entenda somente como "banco de dados de integração".
Capítulo 2 - Modelos de dados agregados
Neste capítulo o leitor começa a entender mais sobre os principais modelos de bases NoSQL e algumas outras partes importantes:
- O que são agregados;
- O porquê da desnormalização de dados nesse tipo de base;
- Transação consistente, ACID, somente em agregados individuais;
- Bases de chave-valor;
- Bases de famílias de colunas;
- Bases de documentos (Firebase Database é um exemplo deste).
Um trecho que percebi como desnecessário é a discussão sobre as diferenças de "modelo de dados" e "modelo de armazenamento", algo que se fosse apenas uma nota de rodapé ajudaria mais na leitura, até porque esse trecho exige um mínimo de conhecimento teórico, por parte do leitor, sobre bases relacionais.
Uma outra crítica é a falta, para este capítulo, de gráficos para as apresentações das bases de documentos e de chave-valor, algo feito com maestria para a base de família de colunas.
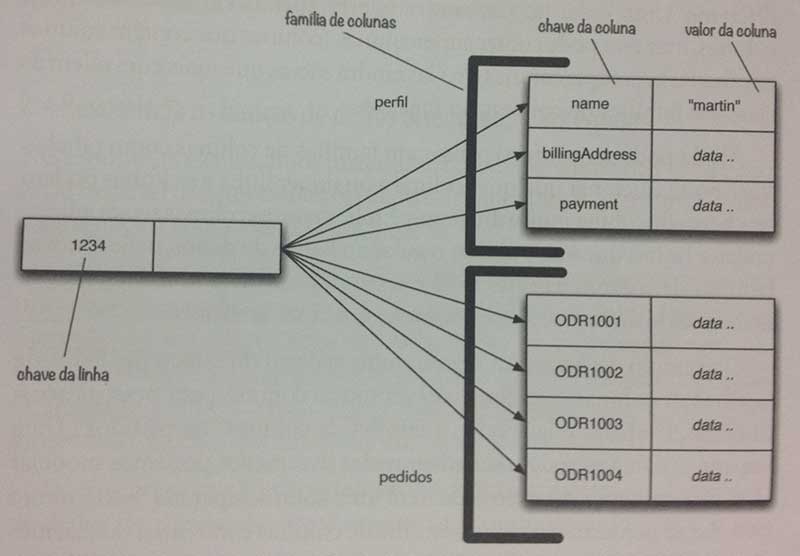
De qualquer forma, mesmo com as críticas, o capítulo é bem completo e de fácil entendimento. Um dos pontos alto dele é a recomendação de leitura, que como informei em resenhas anteriores: é o "para onde ir depois daqui".
Neste capítulo também há os pontos-chave para ajudar na recapitulação.
Um ponto importante é quando os autores deixam claro que o muito sobre "transações" que desenvolvedores conhecem, quando com bases NoSQL de agregados, deve ser trabalhado por eles em algoritmo de linguagem de programação, pois a atomicidade desses bancos é somente em agregados individuais.
Capítulo 3 - Mais detalhes sobre modelos de dados
Neste capítulo o foco é o problema de "muitos relacionamentos" em bancos de dados NoSQL e também em bases de dados relacionais SQL.
Aqui os autores apresentam um outro modelo de bases NoSQL, as bases de grafos que têm algumas características de bases NoSQL (não utilizam a linguagem SQL) e de bancos relacionais SQL (tem ACID).
O importante é notar que os autores, mesmo sendo envagelistas NoSQL, não escondem os prováveis problemas quando o projeto quer tratar bases NoSQL de agregados com relacionamentos entre os agregados.
Eles informam que até mesmo a escolha de uma base relacional SQL, caso a base de grafos não seja viável, é uma melhor opção neste contexto de relacionamentos.
O ponto alto do capítulo é um exemplo abordado em diferentes contextos NoSQL: chave-valor; documentos; famílias de colunas; e grafos. Aqui o leitor percebe que a real diferença entre bases de chave-valor e documentos é o modelo de funcionamento, pois a estrutura é a mesma.
O ponto baixo do capítulo é a explicação exarcebada sobre visualizações materializadas. Provavelmente somente a informação de que em bases NoSQL também é possível tê-las seria o suficiente. Ao final temos os pontos-chave.
Capítulo 4 - Modelos de distribuição
Capítulo pequeno, mas mesmo assim com conteúdo útil. Aqui os autores abordam os modelos de distribuição:
- Servidor único;
- Fragmentação;
- Mestre-escravo;
- Ponto-a-ponto;
- Mestre-escravo / fragmentação;
- Ponto-a-ponto / fragmentação.
O ponto alto do capítulo é a abordagem dos modelos acima onde as vantagens, desvantagens e o "como implementar" são todos bem apresentados.
O capítulo é bem pequeno e se o leitor tiver já alguma experiência que o deixa seguro quando o assunto é bancos de dados, pode ir seguramente direto aos pontos-chave do capítulo, terá ele ali por completo.
Capítulo 5 - Consistência
Neste capítulo, mesmo que de maneira implícita, os autores exigem mais do leitor. Exigem, no caso, um pouco de experiência no trabalho com bancos de dados.
Isso, pois alguns termos técnicos e próprios a bases de dados, mesmo que explicados bem e em poucas linhas, são utilizados.
Os autores mostram algumas possíveis soluções para amenizar os problemas de consistência em bases NoSQL. Informam sobre a importância de "perder de um lado", durabilidade, por exemplo, para "ganhar de outro", velocidade, por exemplo.
Algo confuso foi a excelente explicação sobre o teorema CAP no contexto de bancos de dados. Porém ao final os autores informam que: o teorema não serve para nada no contexto das bases NoSQL.
O tópico de leituras complementares ajuda o leitor no "para onde a partir daqui". E, novamente, os pontos-chave fecham bem com a recapitulação do conteúdo.
Capítulo 6 - Marcadores de versões
Capítulo que seguramente poderia se tornar um tópico do capítulo anterior, Consistência. Conteúdo pequeno e bem explicado.
Os autores mostram o que é um marcador de versão, que este veio para aumentar a consistência quando se tem concorrência de leitura e gravação na base de dados. E, como ponto alto do capítulo, a explicação de "marcadores vetoriais" para bases NoSQL ponto-a-ponto.
O ponto baixo fica com o uso dos termos "servidor verde", "servidor azul" e "servidor preto" sem uma explicação prévia sobre estes e, acredite, nem mesmo o contexto de uso deles da a entender sobre serem somente rótulos de servidores de exemplo.
Aqui, mesmo que curto, também tem os pontos-chave para finalizar o capítulo.
Capítulo 7 - Map-Reduce (Mapear-Reduzir)
Caso você seja um desenvolvedor também do paradigma funcional o entendimento do padrão map-reduce será facilitado a ti. De qualquer forma os autores novamente se saem bem na explicação, utilizando até mesmo gráficos, imagens, para auxiliar o leitor.
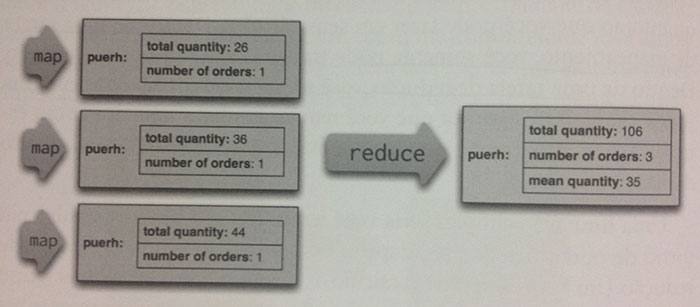
Aqui o foco é apresentar novamente uma das principais problemáticas nas bases NoSQL com agregados: trabalho com relacionamento entre agregados.
Porém dessa vez apresentar o problema junto a solução utilizando o padrão map-reduce. Este permiti conduzir respostas que têm como origem múltiplos agregados em múltiplos clusters, por exemplo.
Os autores fortemente recomendam que o leitor estude a documentação da base de dados em uso por ele, estude ao menos o trecho de map-reduce, pois cada projeto tem seu próprio modelo de uso e a abordagem do capítulo foi generalizada.
Ao final temos os pontos-chave.
Parte II - Implementar
Aqui o leitor começa a ter algo mais tangível sobre tudo já discutido na Parte I, Compreender.
Dos capítulos oito ao onze têm discussões em contexto similares para as diferentes bases NoSQL: chave-valor; documentos; famílias de colunas; e grafos.
Depois voltamos a contextos mais gerais e também teóricos envolvendo principalmente bases NoSQL.
Capítulo 8 - Banco de dados de chave-valor
A partir deste capítulo algumas marcas e bancos de dados em específico começam a ser citados.
Apesar do cunho técnico, os exemplos em código dispensam necessidade de algum computador configurado para a realização dos testes, o foco é apenas em mostrar alguns trechos e que não há a complexidade possivelmente esperada pelo leitor.
Neste capítulo os autores autores utilizam o banco de dados Riak para apresentar uma base chave-valor nos contextos de:
- Consistência;
- Transação;
- Recursos de consultas;
- Estrutura de dados;
- Escalabilidade.
O ponto alto fica com a excelente explicação de termos comuns as bases de chave-valor, termos como: bucket. E também com a apresentação de alguns domínios onde é útil o uso de bases de chave-valor e domínios que dispensam este tipo de banco de dados NoSQL.
Aqui, como em alguns outros capítulos desta segunda parte do livro, não tem pontos-chave e nem recomendação de leitura.
Capítulo 9 - Banco de dados de documentos
Para este capítulo os autores utilizam como base de exemplo o MongoDB para passarem por:
- Consistência;
- Transações;
- Disponibilidade;
- Recursos de consulta;
- Escalabilidade.
Os pontos altos do capítulo são a utilização de imagens que auxiliam na explicação útil a qualquer base de dados NoSQL de documentos. A comparação de comandos SQL com os comandos MongoDB. E o "quando utilizar" e "quando não utilizar", domínios de problema, as bases de documentos.
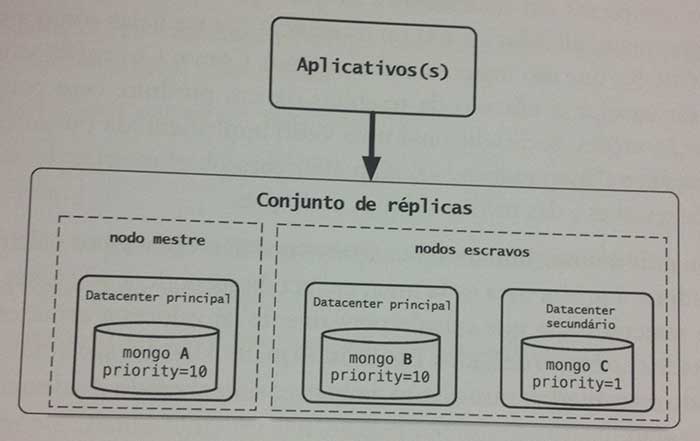
Dê atenção especial aos tópicos de "quando utilizar" e "quando não utilizar" de cada capítulo, pois são consultorias que certamente lhe ajudarão em sua jornada de desenvolvedor ou analista de sistemas.
Capítulo 10 - Armazenamento em famílias de colunas
Aqui o banco de dados utilizado é o conhecido Cassandra - curiosidade: eu já tive de fazer um trabalho de faculdade sobre está base.
Os autores mostram como os domínios atendidos por este tipo de base NoSQL são similares aos domínios de bases de documentos.
Novamente são explicados, com códigos para o Cassandra, os conceitos de: Consistência; Transações; Disponibilidade; Recursos de consulta; e Escalabilidade.
Os pontos altos ficam com a apresentação dos domínios que podem receber bases de famílias de colunas e os domínios que dispensam este tipo de base de dados.
Capítulo 11 - Bancos de dados de grafos
Os autores utilizam aqui a base de dados NoSQL Neo4j, está que é uma base de grafos e também permite o uso da linguagem Gremlin.
Alias este é um dos pontos curiosos abordados no capítulo, os autores informam sobre o padrão Blueprints entre os bancos de dados de grafos que faz com que a maior parte deles aceitem a linguagem Gremlin como a linguagem principal de manipulação de dados, mesmo quando houverem outras presentes.
O ponto baixo do capítulo fica com o tamanho do tópico "Recursos de consulta", este poderia seguramente ser dividido em ao menos dois.
Os pontos altos novamente ficam com as apresentações de domínios sobre "quando utilizar" e "quando não utilizar" bases de grafos.
Capítulo 12 - Migrações de esquema
Aqui os autores voltam a falar sobre algo comentado várias vezes na Parte I do livro: mudança de esquema de dados.
Mesmo as bases NoSQL não tendo esquemas de maneira explicita como as bases relacionais SQL, os autores abordam os problemas e soluções, estratégias, utilizadas nestas últimas para que em tópicos avançados do capítulo, tópicos somente sobre bases NoSQL, as explicações das estratégias para estes bancos sejam facilitadas.
Isso, pois algumas estratégias de bases relacionais SQL são úteis a problemas de esquemas implícitos em bases NoSQL.
O ponto alto do capítulo fica com as explicações detalhadas de soluções de migrações de esquema para bases NoSQL em geral, mesmo as bases de grafos. Explicações que levam em consideração a camada de programação de domínio dos softwares, pois é ela que contém o esquema de bases NoSQL.
Neste capítulo os pontos-chave estão de volta.
Capítulo 13 - Persistência poliglota
Para mim um dos principais capítulos do livro, é aqui que o leitor percebe que o conhecimento adquirido é uma "carta de baixo da manga", pois com exemplos em texto e em gráficos os autores mostram ao leitor a importância de conhecer múltiplas bases para abordagens eficientes nos aplicativos de hoje.
Aplicativos que têm dentro deles diferentes domínios que necessitam de diferentes tipos de base.
A bordagem de utilizar uma mesma base de dados para todas as solicitações do software é considerada pelos autores uma abordagem antiga e que DBA (administrador de bancos de dados - database administrator) algum deve ter o conhecimento de apenas um modelo de banco de dados.
Eu mesmo tive já de utilizar mais de uma base de dados quando trabalhava com o domínio do problema de telemetria de barragens. Os dados de medições entravam aos montes a cada segundo e o sistema cada vez mais lento. Utilizei duas bases relacionais e mesmo assim continuei enfrentando problemas de velocidade.
Hoje em dia seguramente, ao menos para as medições, eu utilizaria uma base de chave-valor ou de documentos.
Este é mais um daqueles capítulos que precisam de atenção total na leitura. Ao final terá também os pontos-chave.
Capítulo 14 - Além do NoSQL
Mais um capítulo curto e que poderia ter sido agregado ao capítulo 13, agregado como um tópico.
O objetivo aqui é mostrar os pontos fortes e fracos de bases de dados pouco utilizadas e que podem ser usadas junto a bancos NoSQL. Bases como: de persistência de objetos; de persistência em XML.
O que tem de inédito é a explicação completa do padrão Event sourcing.
Ao final temos os pontos chave.
Capítulo 15 - Escolhendo o seu banco de dados
Fechando o livro com chave de ouro, aqui os autores buscam a reflexão por parte do leitor, informando a importância de ainda levar em conta as bases relacionais SQL, buscando sempre a simplicidade, porém sem sacrificar a qualidade, eficiência do projeto.
O ponto fraco do capítulo é quando os autores recomendam que bases NoSQL não sejam utilizadas em produção, pois ainda não estão maduras. Para isso temos de levar em conta que o livro, apesar de lançado em 2013, foi escrito em 2011, provavelmente nessa época essa era uma recomendação inteligente.
O ponto alto fica com a ênfase em informar ao leitor a importância de sempre criar uma camada de acesso aos dados, algo que facilita, por exemplo, a mudança do banco de dados caso necessária.
Neste capítulo também há os pontos-chave e algumas considerações finais que incentivam o leitor a continuar a jornada de estudos e prática em bases NoSQL.
Ponto negativo
Um ponto negativo além dos já abordados no decorrer da resenha:
- Alguns termos, comuns a usuários do Linux, são utilizados. Algo desnecessário sabendo que haviam termos sinônimos e de entendimento geral.
Pontos de destaque
- Há muitos gráficos, imagens, que facilitam consideravelmente o entendimento dos assuntos;
- Apesar dos códigos, o livro é somente de leitura, dispensando a necessidade de uma máquina ao lado. Para um livro introdução isso é excelente, o foco é a teoria;
- Não há receio em mencionar também bases NoSQL pagas, tendo em mente a qualidade delas;
- As dicas de leitura durante o livro suprimem a necessidade de um capítulo final indicando o "Para onde ir partindo daqui".
Conclusão
Primeiro, achei prudente colocar aqui os comentários de um livro sobre NoSQL, pois este é um conteúdo inevitável para aqueles que são (ou pensam em se tornar) programadores ou analistas.
O livro é bem completo para um livro introdução, um pouco mais de 200 páginas, e por exigir somente leitura, em pouco tempo, alguns dias, é possível lê-lo por inteiro e ainda com um bom entendimento.
Note que mesmo sabendo que o Firebase Database abstrai em muito as configuração do NoSQL em uso, configurações como definição de quórum de gravação e de leitura, por exemplo. Conteúdos teóricos de NoSQL ainda são de grande utilidade a usuários dessa base de dados do Google, pois para a definição de chaves e de esquema implícito ainda é preciso um estudo detalhado.
Então é isso, não deixe de dar as suas dicas de leitura e de bases NoSQL e de informar o que achou da resenha acima.
Não esqueça de se inscrever na 📩 lista de e-mails para receber os conteúdos exclusivos e em primeira mão.
Abraço.



Comentários Facebook